building fullstack
clusters 🔗, containers 🐳 and some creativity 🎀
abstract: i built a service to spin up a custom public one record instance in a few seconds. while doing so i learned a lot of details about all the technologies involved. in this porject i got as full stack as you can when developing your own cloud-like service.
disclaimer: writing this blogpost i felt some corporate pressure and the language is chosen accordingly. nowadays i dont enjoy that language anymore but i wanted to keep the blogpost up as i really enjoyed implementing the project and learned a lot. in other words, this blogpost sounds a bit too much like linkedin/ai speak for my taste. (edited: 03.02.26)
i think with this post i got to start at the beginning: some months ago i was curious to learn more about building large systems. i started looking more into high availability, systems design, container orchestration and decided the best way to learn about all of these things would be to apply them and build out a project that was meant to scale.
the goal of this blogpost is to talk a bit about all the technologies i encountered and experimented with along the way, talk about the experiences i had with them and present the service that resulted from this little excursion 🧑🏻🦯➡️.
so, what did i build? naturally i thought of the problems that i had encountered in the pasts where i would have wanted a solution to exist and that could have been solvable with this ✨enterprise scale✨, automation and all the goodness that modern companies want to make us believe we need (i say it like this because i am a big fan of decentralization which intends to make hyperscaler clouds less necessary but nevertheless i find the technologies behind it very interesting).
in the past i have been working as a researcher in the air cargo industry (i wrote a quite lengthy blogpost on that in case you are interested) where i encountered the data standard which iata is currently trying to make the industry adapt. currently there is little tooling and services around the standard. an issue i already tried to tackle in the past with a tool called ne:one play which tried to improve understanding for the data structures of the data standard by improving the visualization and interactability of data stored in that standard. another annoyance when using this standard is setting up the server itself. its quite ok on localhost but once you want to do it publicly there is some hassle involved. well that sounds like a task for ✨ enterprise ✨, doesnt it? 👨🏻💼
(tl;dr;) so i decided to create a service where you can host such a one record server on the public internet with just a few clicks. i mean what is more ✨ enterprise ✨ than basically building your own cloud?
hardware
when i started the project i had no place to reasonably host the service so started by creating my own little setup. This resulted in a cluster that could almost be considered an affront to decency. in a one gig subnet a heavily modified thinkpad t420, a 2012 mac mini and a thinkpad x1 carbon (both the thinkpads were past bargain buys, some might even call them steels 😏, from the german equivalent of craigslist) hugged together to create a proxmox high availability cluster with a shared ceph drive. together this made for 12 cores / 24 threads and 48gb ram which is actually quite acceptable for what it is.

this abomination was then publicly available on the internet on port 80 and 443 via keepalived for loadbalancing, a reverse proxy and a tailscale to route the client from my domain through the firewall right into this subnet of doom. it was a real fun setup and i learned a lot about clusters, high availability and networking in the process.
i started developing on this setup but noticed quite quickly that just for the development it wasnt strictly necessary. this was a setup made for deployment (honestly it was made to be better not used but im missing the point) and the t420 fans were getting quite loud from under my sofa. Right around this time i also got access to a server in my university and was able to convince the local sysadmin to open ports 80 and 443 in the firewall for me which meant i could make it accessible from the web. this was a much nicer development experience since it had a public ip (meaning no necessity for the tailscale/dyndns magic i had employed before) and since it was a server (24 threads, 128gb ram, 10gb vram 😏) it was also much more performant than my frankensteined cluster. although in my opinion the cluster was way cooler i disconinued it for now and kept developing on the new server.
In the future i want to build a proper little homelab, i am really eyeing those second and third gen used epyc cpus 👀 although there are still a bit pricy atm. getting three of those nodes (the minimum for proxmox high availability) is atleast for now with the current pricing and rising electricity costs in germany more than far fetched 😅.
systems design
before we can get to the systems design the minimal set of features has to be defined. with my service a user should be able to
- create an account
- create, start, stop, delete one or more public onerecord server instances
- get info about the state (up, down, etc) and system load of the instance
- create access tokens for the server instance
- reset, share or download (from other users that have shared) the storage of the one record instance
up until now this project has had the working title 1r.erik.gdn as this was simply the subdomain where i had hosted it for the time being (1r meaning one record) but then i decided that this was the (onerecord) playground. therefore the two terms are being used synonymously in the further text.
i had a lot more feature ideas (especially with ne:one play and ai/llm integrations), but (almost all of) these additional features would not need changes in the systems design realm and also i like to keep things simple (KISS) when building mvps, especially as the idea behind this is to be an exercise in ✨ enterprise ✨ and not necessarily focused on one record. so lets focus on those criterias. the system should be able to
- support unlimited users *
- have high availability / dynamic scaling in mind
- have cold start functionalities for one record instances that havent been used in a while
(* this is highly theoretical of course, on the one hand as there quite little people that would be interested in such a service (lol) and on the other hand as i am obviously hardware resource limited. the intention is to design the service in such a way, that simply adding nodes to the cluster on which the service is running would enable more users. meaning to design the service in way where is can easily scale horizontally.)
with that out of the way and being the proper ✨ enterprise ✨ engineers we obviously are we can start planning the microservice architecture.

this project is completely based around an api. this apis job is to handle auth, the usual crud operations and to take in the actions by a user to be applied to their one record deployments. as the whole project is about ux we obviously need a frontend service, and the api service also necessatates a simple database for storage. in the interest of decoupling things and seperating concerns i want to have a separate worker microservice for actually managing the whole container orchestration. then we need a separate container cluster (depending on later needs this could be docker, podman, docker swarm, kubernetes etc) where the actual one record instances are then hosted and served from. to store the one record database content and other miscellanous data (such as images etc.) a blob storage is necessary. once all that is in place requests to the service have to be routed properly and for that i used a reverse proxy. also depending on the scale in production a load balancer could make sense but for now i wont bother with implementing that.
More optimzations are likely to be added with scale (such as a more distributed / sharded database architecture etc) but for now (especially looking at the limited tam) i will settle with this rather simple design.
as these are microservices, all of them (execept the database) could be then scaled horizontally using kubernetes, in that setup one could also simply use the kubernetes ingress for load balancing. the only possible exception here is the container system but this can also be easily managed by simply adding compute nodes to a docker swarm cluster (for example). Another note, currently i have some hand implemented message brokers for the api-worker communication using my database together with some update triggers, with scale this could become a bottleneck and should likely be replaced with a dedicated message broker service aswell as using the usual scaling techniques for improving the actual database itself.
To make it very clear, the idea here is to build a playground where everyone can (for cheap) have their own little public one record instances to learn about the standard and experiment with it. it is not to create hyperscaled one record instances which can handle hundreds of thousands transactions a second, that is an entirely different problem which requires different systems designs solutions and would be much less generalizeable to other systems design architectures (and therefore not exactly the exercise i was looking for with this project).
software
when implementing i tried to focus on creating actually maintainable code. this resulted in the current system being the third implementation of this concept and finally i am quite content with it. the first time it was just a hack, the second time had a lot of the features working but grew to be a really bad developer experience whenever i needed to add features (especially because i had chosen suboptimal data structures) and now, this last time, it is quite comfortable to work with. while we are still at the fundamentals, for this project i tried to use only non proprietary technologies, i did not want to learn the cloud environment and tooling of a specific cloud provider but i wanted learn the concepts around it. in general i am a firm believer in open source and selfhosting as in my opinion it is the path back to a more free internet. for improved developer experience i added seperate dev and prod environmnets with the dev environment enabling all the debug logging and also including hotreloading on code changes to speed up development.
the part that is managing all the deployments is the worker. after i created the state diagram of all the possible states a deployment could be in (it is quite involved) i started implementing it. the worker simply takes signals from a queue and processes them. this means interacting with the docker (or other container system) daemon together with some storage system operations. due to the queue architecture this makes the worker very decoupled from the rest of the architecture, the workers could be completely horizontally scaled with them just picking jobs of the queue without experiencing any lockups. i also added a middleware to the central reverse proxy so the requests going to a one record deployment could be tracked, this enabled me to implement cold starting for the deployments. if a deployment was not accessed for a prespecified amount of time the it is being paused and only started up again once it is requested by a user request. with some optimizations i got coldstart times to below 2 seconds which is not insanely fast but more than acceptable in my opinion, especially considering that this mechanism saves a huge amount of ressources by only running the deployments that are actually being used at the moment.
The Backbone of this is a strong database structure, i focused on a normalized design with performance oriented indexes and optimized queries. i see the database being the easiest point for improvement as it currently serves multiple purposes which could be splitted up into seperate more dedicated services. for example an in memory db would be much more reasonable for the cold start functionalitys (i.e. redis) and the beforemetioned message brokers would also be an obvious performance improvement.
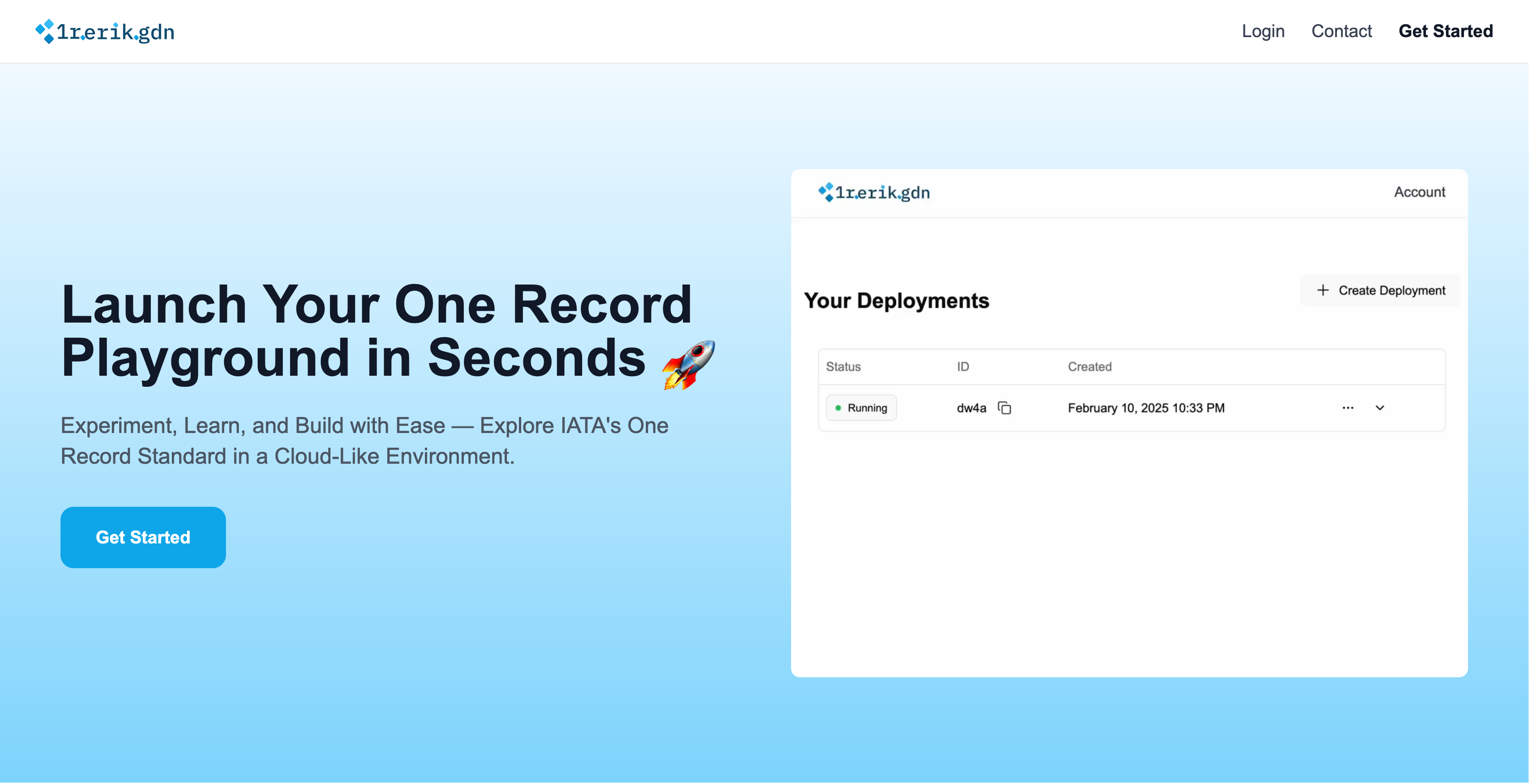
lets now get to the user facing part of the project. the frontend is your standard nextjs, i employed heavy use of shadcn as i feel like you cant do anything wrong with it, especially after customizing a few parts i dont even feel like it feels too much like a cookie cutter ui. now to a real first, i got to use framer motion for the first time and while it was a bit confusing at first and i feel like the performance is suboptimal the animations really do improve the user experience immensely in my opinion. i mean its the sole reason that little demo video looks as cool as it does. implementing the websocket especially with the correct updating of the deployment table was a bit challenging but honestly the frontend was quite straight forward. i mean the fact that i added a confetti animation when the user clicks the ‘add deployment’ button (and wait until you see the 404 page…) tells you that i really tried hard to make it fun but in the end it just does its job and thats all it needs to do.
brand design
in the past i always tried to delegate design work away from me and this time i also asked around if anyone i knew who was into brand/ui/ux design was interested in sketching up some mockups, after getting the feedback from a lot of people that they were currently in exam season and therefore really couldnt manage another side project i felt like it was time test my rusty design skills and give it a try myself. i installed figma again and tried to piece something together that resembled some kind of brand identity. i went with my first intuition and after pouring a bit of time into it i was ok with the result. to be totally honest i knew one could spend days here but i just wanted to get some design concept that i could work with and so i ended up with this.

When i started with the brand design i also intended come up with some fancy name to use with the project but after some time i ended up just using my internal naming. honestly it even has some odd cold coolnes to it in my opinion. and also with it being a side project i am quite ok with that as it meant i wouldnt be tempted to buy another domain, also i simply like the more technical touch it has.
future outlook
Well this project was a lot of fun and i learned a lot about all kinds of things. i am publishing this blogpost to kind of mark this project as finished. i think i got to a point where all the technical difficulties are solved and making it truly production ready would just be more refining (and some legal paperwork as well). in the unlikely case that i misjudged the tam here i would be happy to use this project as an opportunity to run a project in production with real users but to make it very clear for now, this is not publicly available, what i showed here can currently not be used by the public. i am saying it this clear so i am not forced to doxx myself by having to put an impressum on my site etc. there is no commercial intentions here at all, this was a project with the pure goal of gaining knowledge and experience. if you have thoughts or questions on the project i would love to hear from you. with all that said, i hope you got some value out of this.
one more note:
the notes on being ✨ enterprise ✨ were kind of to make fun of the concept. i like the challenge of designing for large scale and took some considerations to make this architecture scalable, there still might be bottlenecks in here (its even pretty likely and i am very happy to hear from you about them 🤓). how well this software ’enterprises’ and scales only large scale testing will tell and i currently dont have the infrastructure and users to do so xd.